I had not intended to review the MET’s online collection as my online resource, but this week’s readings, particularly Kirton and Terras, made me want to bring the MET into the discussion. In this post, I will weave in a review of the MET’s online collection while also putting this digital resource in conversation with relevant or tangential writings about other digital projects. I want to preface this post with the acknowledgement that some of the ideas I am going to present and engage with could be a bit idealistic, but they are ideas that are still worth considering, but I digress.
As more and more cultural heritage institutions are working to digitize parts or all of their collections, questions naturally have and will continue to arise regarding the use, circulation and fate of these digital images. In “Where Do Images of Art Go Once They Go Online? A Reverse Image Lookup Study to Assess the Dissemination of Digitized Cultural Heritage,” Isabella Kirton and Melissa Terras begin to address the afterlife of an artwork once its digital surrogate is put on the web. Kirton and Terras conducted a study in which they used reverse image lookup (RIL) technologies to assist in “assessing the impact of digitized content,” specifically paintings, from the National Gallery, London. One aspect of this study that I found peculiar was that the RIL technologies used by Kirton and Terras are normally employed by commercial entities curious about how their visual data is being reused. This gave me pause only because often times the goals/aims of the commercial sector are at odds with those of the cultural heritage field. While I do think there are ways in which both industries can utilize the same technologies and resources, I do think its worth considering the implications of a museum using technologies designed for commercial, for-profit organizations.
As Kirton and Terras write, such a information about the reuse of digital images “could be used by cultural heritage institutions to justify the investment in digital materials and in making resources available to others for reuse.” This is an excellent point, especially given that digital projects can be expensive (though not often hard to pitch as most loves new and flashy technological projects) but the ‘why’ of a museum desiring to track the online reuse of their images was a not a large focus of Kirton and Terras’ article. While knowing where digital images of an institution’s artworks end up on the web could be useful in some instances, in others it seems to me to be a waste of labor, technological resources and time.
Thus, as I read, I wondered why else a museum would want to know where on the web their images were being used. I then wondered why a museum should want to know, or, more specifically, instances where it would be particularly illuminating. This brings me to the second reading for this week, “It’s All About the Stuff: Collections, Interfaces, Power, and People” authored by Tim Sherratt. Sherratt talks about his project, “the real face of White Australia,” which was, in his words, an experiment that utilizes facial recognition technology to detect various faces in the digital images held and hosted online by the National Archives of Australia. The project was inspired by challenging a dominant narrative and reframing the nations history specifically when it came to the notion of ‘White Australia.’ Contrary to popular belief, Sherratt writes, the country of Australia has been a historically diverse place where people form many nations, including China, Japan and Syria, amongst others, not to mention the country’s indigenous population. Using open source software, Sherratt detected the faces within thousands of photographs and built a database populated by said faces. What resulted was a new way to see and interpret government records – Sherratt was able to use his database to reveal that the myth of a White Australia was just that. This project allowed for some reframing and recontextualizing to occur, and shed light on the fact that archival records and interfaces are rarely neutral. Additionally, it had the potential to gave back a sense of ownership and power to minority groups in Australia who have been continually written out of the story. I wondered if the National Archives of Australia knew about this project, and I have to assume they must. Had they not, they could have used similar RIL software to see the ways in which others have been able to utilize their collections to tell alternative stories and open up new avenues of research and interpretation. An instance like this is one in which I think it could be extremely beneficial for institutions to know how their digital collections are being used, especially if it could foster relationships between independent scholars and institutions or provide avenues for institutions rethinking how they frame their collections.
Now, least you thought I forgot, to return to my initial mention of the MET’s online collection. I thought of the MET for several reasons, the first being that in 2017 the MET announced a new commitment to open access, a choice unparalleled in the museum world given the scope, size and significance of the MET’s collection. The reason this came to mind as I read the Kirton and Terras article was that I initially wondered if the article would be about museums using RIL software to become copyright police. While that wasn’t the case, it did provide me an opportunity to get on the open access soap box, which I always appreciate. While there are financial and rights related restrictions for providing open access that many institutions face, I think it is of paramount importance that most cultural heritage institutions turn towards open access initiatives where they can. When we think about providing more access, and even possibly decolonizing our histories and the institutions upon which they are built and supported, I think open access plays a huge role. As we saw with Sherratt’s project, having unrestricted access to records and historical images can open up a whole world of possibilities when it comes to innovative and necessary digital humanities projects.
Sherratt also talks about the inherent power and dangers that come along with the ways in which institutions classify and organize their collections. While it is (I think) unarguably great that the MET provides open access to all of their digital images, they do still organize them in more traditional museum classifications. Date/Era, Geographic Location, and museum Department are just a few filters that can be applied within a search, but they all, especially the department, seem to me to connect strongly to a traditional Eurocentric way of organizing information. I would love to see an institution as large as the MET commit to novel ways of enabling searches and enhancing discoverability using alternative systems, vocabularies and the like. (I realize this would require vast amounts of time, research, labor and money.)
In terms of how these ideas can be incorporated in my own work I think about the ways in which artists archives, or archives more broadly, are organized. How can archives enable alternative methods to classify, organize and present their materials online in ways that encourage new types of contextualization, discovery and scholarship? I would love an online archive project where archivists and information professionals could work directly with the artists whose work they are digitizing, preserving, organizing and presenting to come up with personalized vocabularies and ways of classification. Who knows if this would result in the most usable or traditional digital art history project, but I think there is something important in the idea of presenting art and archival material in ways that feel appropriate to their creators.
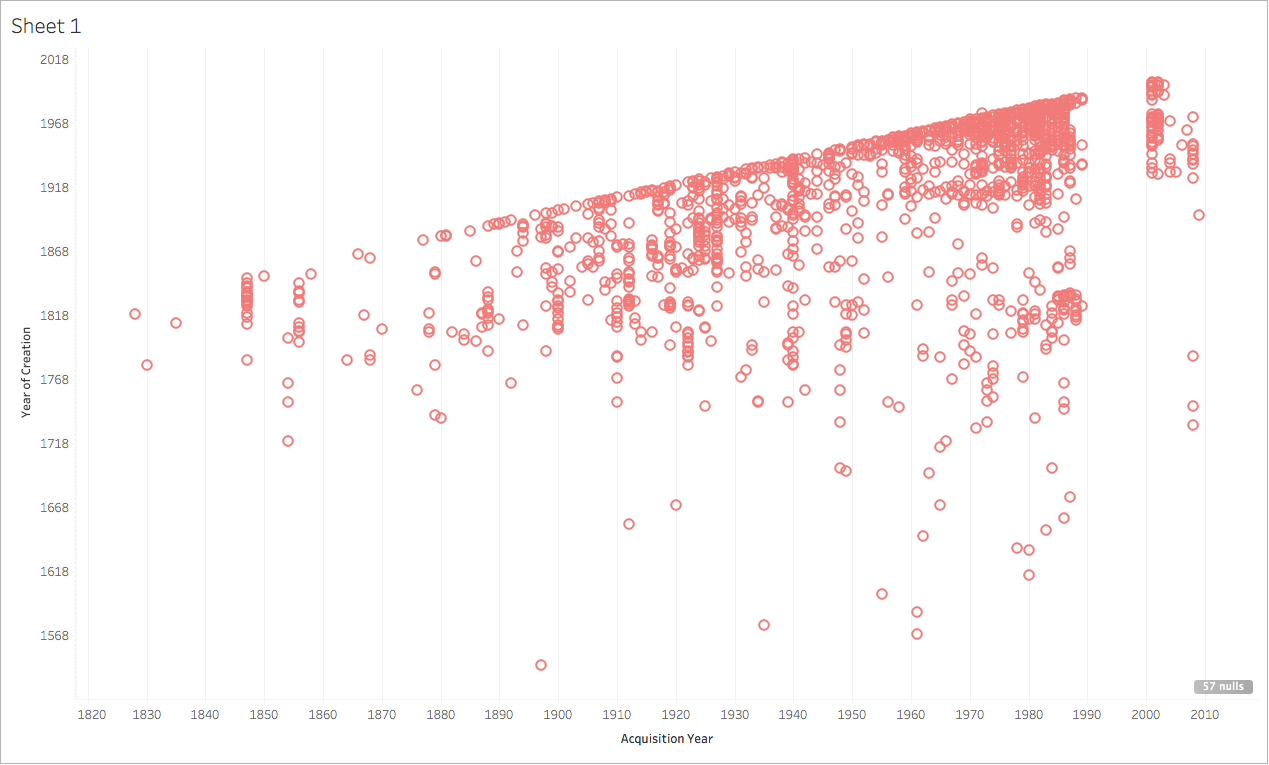
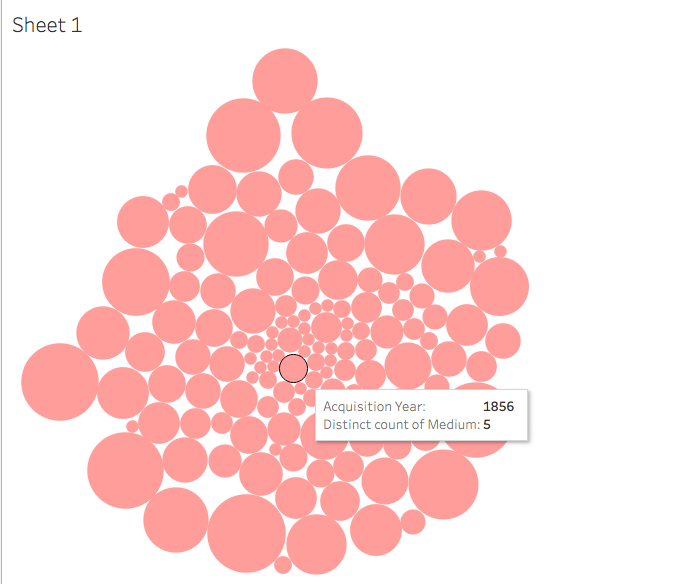
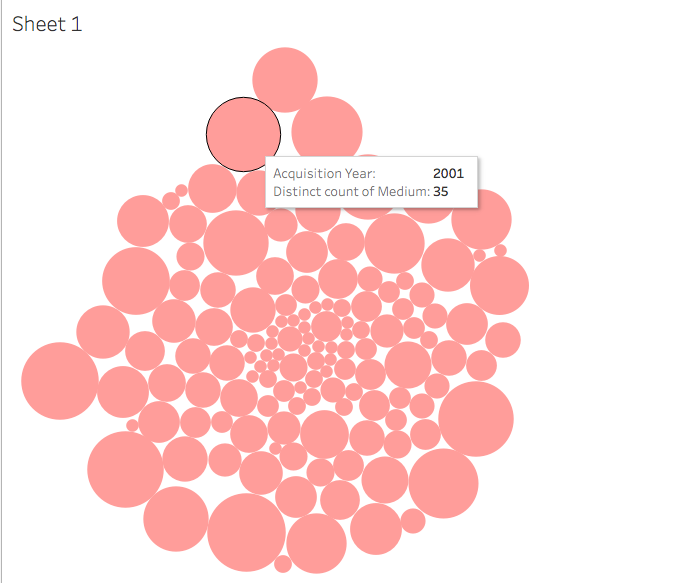
 As a dual degree student (library science/art history) I am most interested and excited by the intersection of archival work and art history. A question that this week’s readings and discussions have made me ask is can archives learn anything from digital art history? Are there ways in which arts archives can present their materials that is more dynamic? Can we move from the digitized to the digital, so to speak?
As a dual degree student (library science/art history) I am most interested and excited by the intersection of archival work and art history. A question that this week’s readings and discussions have made me ask is can archives learn anything from digital art history? Are there ways in which arts archives can present their materials that is more dynamic? Can we move from the digitized to the digital, so to speak? [Example of an image that could contain linked information within an online archive]
[Example of an image that could contain linked information within an online archive]